Imagination-Augmented Agents for Deep Reinforcement Learning
Unlike most model-based RL and planning methods which prescribe how a model should be used to arrive at a policy, I2As learn to interpret predictions from a learned environment model to construct implicit plans in arbitrary ways, by using the predictions as additional context in the policy.
- Introduction
- 2. Architecture
- 3. Architecture Choice and setup
- 4. Experiments
- 5. One model for many tasks
- 6. Related work
- Year: 2018
- https://arxiv.org/pdf/1707.06203
Imagination-Augmented Agents (I2As) is an architecture combining model-based and model-free aspects of DRL.
Unlike most existing model-based RL and planning methods, which prescribe how a model should be used to arrive at a policy, I2As learn to interpret predictions from a learned environment model to construct implicit plans in arbitrary ways, by using the predictions as additional context in deep policy networks.
Introduction
- Model-free RL, directly mapping raw observations to actions or values, requires large amounts of data. It also doesn’t readily generalize to new tasks in the same env.
- Model-based RL addresses this by enabling the model to “imagine” about the future while avoiding poor trial-and-error decisions
- Learning the model first (if needed) will enable better generalization across states, exploit unsupervised learning signals, remain valid across tasks in the same env, resulting in data efficiency.
- Model based RL can also scale performance with more computation by increasing the amount of internal simulation
- In complex domains with no simulation, model-based RL performance suffers from model errors resulting from function approximation. These compound during planning.
- Such model imperfections in complex domains make model-based RL unable to match model-free RL
- I2A seeks to address this by enabling the model to learn to interpret its imperfect predictions
Discussion:
- I2A combines model-free and model-based ideas to give imagination-augmented RL —Learning to interpret env models to augment model-free decisions.
- It’s able to use imperfect models, including models without reward predictions
- I2A is less than an order of magnitude slower per interaction than the model-free baseline. Pondering before acting trades off env interactions for computation
- In Sokoban, I2A compares favourably with the MCTS baseline with a perfect env model
2. Architecture
- To augment model-free agents with imagination, authors use environment models. These are models which can be used to simulate imagined trajectories.
an environment model(EM) is any recurrent architecture which can be trained in an unsupervised fashion from agent trajectories: given a past state and current action, the environment model predicts the next state and any number of signals from the environment.
-
The env model used here is builds on action-conditioned-next-step predictors — take the current action and observation (or observation history) and output the next observation and reward.
-
The model has an imagination module. This has a policy $\hat{\pi}$ that predicts the action $\hat{a}$ for an observation, and the env model (EM) which takes in the same observation and predicted action $\hat{a}$ to give $n$ trajectories $\hat{\mathcal{T}}, … \hat{\mathcal{T}_n}$. Each imagined trajectory consists of predicted observations and rewards (outputs of the env model) $\left(\hat{f}{t+1},\dots, \hat{f}{t + \tau}\right)$ upto the rollout length $\tau$
- These outputs are fed into a rollout encoder (LSTM + Conv net) $\mathcal{E}$ that processes the imagined rollout as a whole and learns to interprete it by extraction of info useful to the agent.
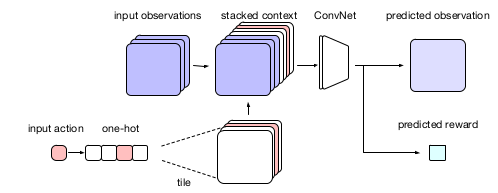
Figure 1: A conv network transforms the concatenated input into a pixel-wise probability distribution for the output image and a distribution for the reward
\[e_i = \mathcal{E}(\mathcal{T}_i)\]3. Architecture Choice and setup
3.1 Rollout strategy
- For each rollout $\mathcal{T}$, the first action in the $i^{th}$ rollout is the $i^{th}$ action in the action set $\mathcal{A}$. Subsequent actions are produced by the rollout policy $\hat{\pi}$ This means there’s one rollout for every possible action
- The efficient policy rollout strategy identified by the authors is distilling an imagination-augmented policy into a model-free policy
- The distillation strategy consists of a model-free network $\hat{\pi}(o_t)$, and adding to the total loss an auxialliary cross entropy loss between the imagination-augmented policy $\pi(o_t)$ on the current observation, and $\hat{\pi}(o_t)$ on the same observation
- Imitating the imagination augmented policy ensures the internal rollouts are similiar to the real environment trajectories (with high reward)
- The approximation also gives a high entropy policy, balancing exploitation/exploration
3.2 Components
- The encoder is an LSTM with a conv network. Feautures $\hat{f_t}$ are fed into the LSTM in reverse \(\hat{f}_{t+\tau}\) to $\hat{f}_{t+1}$ to mimick Bellman backup. However, authors say this isn’t neccessary
- The aggregator concatenates the summaries
- The model free path consists of a Conv net and and FC
- Pre-training the env model before embedding it(with weights frozen) has faster runtime than jointly training with the agent
- Training data is collected by partially trained model-free agents as random agents see fewer rewards in some of the authors’ domains.
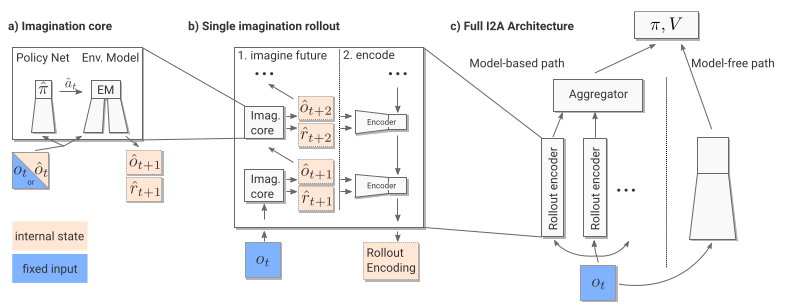
Figure 2: I2A architecture: $\hat{}$ represents imagined quantities
3.3 Agent training and baselines
- With a fixed env model, the rest of the parameters were trained on A3C.
Baselines:
- Standard model-free agent: This has conv layers, an FC and a final FC that outputs the policy logits and value function
- Copy model agent: To verify the env model in I2A contributed to performance increase, authors replaced it with a copy model. This simply copy returns the input observation.
- The agent doens’t use imagination
- This model is equivalent to having policy logits and as outputs as final outputs from an LSTM with skip connections
4. Experiments
4.1 Sokoban
- Sokoban involves pushing a box to a target location
- I2A, with rollouts of length 5, outperforms the baseline
- Longer rollouts increase performance. This environment has 50 steps. Authors however say longer rollouts have diminishing returns for I2A — length 15 is slower than 5 / 50 (total steps)
- Number of frames needed for env model pretraining < 1e8. I2A outperforms baseline after seeing 3e8 total frames
4.2 Learning imperfect models
- Surprisingly, a poor model slightly outperforms a good model in I2A. Authors say this is because of random initialization or regularization provided by the imperfect model
- In contrast with Monte Carlo (MC) search, that performs really bad with an imperfect model
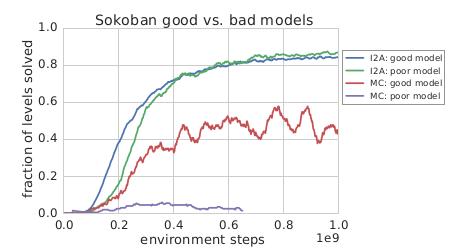
Figure 3: I2A run
- Learning a rollout encoder is what enables I2A deal with imperfect models
- I2A with a copy model (obs → f(obs) → same_obs) performs far worse. This shows the importance of the env model
- I2A trained on an env model predicting no rewards, and only imagined observations, performs worse. But it (almost) catches up after much longer training steps (3e9). So reward prediction is helpful for I2A, but observations alone are informative enough
- Assuming a nearly perfect model, the number of imagination steps required to solve a number of levels is smaller in I2A than in MCTS baseline e.g 1.4k to 25k for 87% solved levels
5. One model for many tasks
- This was tested on a game requiring the agent to eat health pills while running away from ghosts i.e., 2 tasks
- I2A seems to be able to predict the ‘instruction’ about which task to solve(i.e., eat or run) in the environment by predicting a task reward from the model
6. Related work
Model imperfection [is also] in robotics, when transferring policies from simulation to real environments. There, the environment model is given, not learned, and used for pretraining, not planning at test time.
- Gaussian processes can also deal with model uncertainty but at high computational costs and also can’t learn to compensate for possibly misplaced uncertainty
- Models that create synthetic data increase data efficiency e.g Dyna, but this isn’t used at test time